HITCON CTF 2017 Secret Server Revenge 解いてみた
HITCON CTF 2017で出題された Secret Server Revenge を海外のWriteupを参考に解いてみたので、自分なりの言葉でまとめてみます。
本番中はSecret Serverに着手し、フラグ半分まで得ましたが、方針が間違っており時間内に全て特定できず。。。後日、時間内に解いたチームメイトにチーム内の勉強会で方針を聞いて解くことができたので、その拡張の問題であるSecret Server Revengeを解いてみました。
続きを読むCSAW CTF 2017 Write-up
CSAW CTF 2017にチームm1z0r3で出ていました.
Misc 100とCrypto 350を解いたのでそのWrite-upになります.
CVV ( Misc 100 pts)
CVVとはCard Verification Valueの略で,クレジットカード番号のこと.
netcatでサーバに接続すると,"I need a new Visa!" , "I need a new American Express!" のようにクレジットカード会社の番号を求められる.なお,newと付いているのは一度の接続で同じ数字を使いまわしてはいけないということを表している.
つまりこの問題は,指定された会社のクレジットカード番号として正しい番号を送り続ける問題である.では,クレジットカードの番号として正しい値がどのような値かというと,以下の二つを満たす値である.
1.クレジットカード会社ごとのプレフィックスというのは決まっていて,Wikipediaにも記載されている.詳細はこちらを参照してほしい.
2.Luhnアルゴリズムというのはクレジットカード番号を決定する際に用いられるアルゴリズムである.1954年にハンス・ペーター・ルーンという当時IBMの研究者だった方が考案したアルゴリズムで,当初は特許化されていたが現在ではISOにより世界標準となっている(ISO/IEC 7812).
このアルゴリズムの説明は割愛するが,こちらもWikipediaに詳細が記載されているので参考にしてほしい.なんとPythonのコードまで記載されていたので拝借した.
スクリプトを書いて何度か試行していると,求められる条件が以下のように変動することがわかる.
- "I need a new ...": 特定のクレジットカード会社の正当な番号を答える
- "I need a new card that starts with ...": ある数列で始まる正当な番号を答える
- "I need a new card that ends with ...": ある数列で終わる正当な番号を答える
- "I need to know if ... is valid! (0 = No, 1 = Yes)": 与えられた番号が正当かどうか答える(16桁?)
これらによって条件分岐するようなスクリプトを書いた.
# coding:utf-8 from m1z0r3.crypro import * import string from random import randint import time def rand_num_str(n): ret = "" nums = string.digits for i in xrange(n): ret += nums[randint(0,9)] return ret # Reference: # https://ja.wikipedia.org/wiki/Luhnアルゴリズム#.E5.AE.9F.E8.A3.85.E4.BE.8B def check_number(digits): _sum = 0 alt = False if digits[0] == "0": return False for d in reversed(digits): d = int(d) assert 0 <= d <= 9 if alt: d *= 2 if d > 9: d -= 9 _sum += d alt = not alt return (_sum % 10) == 0 def main(): remotehost = "misc.chal.csaw.io" remoteport = 8308 s,f = sock(remotehost, remoteport) stage = 0 while True: stage += 1 print "Stage %s"%stage recv = read_until(f).strip() print recv send_item = "0" if "flag" in recv: break if "Visa" in recv: while not check_number(send_item): send_item = "4"+rand_num_str(15) elif "American" in recv: while not check_number(send_item): send_item = "3"+rand_num_str(14) elif "Master" in recv: while not check_number(send_item): send_item = "5"+rand_num_str(15) elif "Discover" in recv: while not check_number(send_item): send_item = "65"+rand_num_str(14) elif "starts with" in recv: starts_num = recv.split()[-1][:-1] print "[+] starts with %s"%starts_num send_item = starts_num+rand_num_str(16-len(starts_num)) while not check_number(send_item): send_item = starts_num+rand_num_str(16-len(starts_num)) elif "ends with" in recv: ends_num = recv.split()[-1][:-1] print "[+] ends with %s"%ends_num send_item = rand_num_str(16-len(starts_num)) + ends_num while not check_number(send_item): send_item = rand_num_str(16-len(starts_num)) + ends_num elif "need to know" in recv: verif_num = recv.split()[5] print "[+] verification number: %s"%verif_num if len(verif_num) %2 == 1: print "奇数やで" send_item = "0" elif check_number(verif_num): send_item = "1" else: send_item = "0" s.send(send_item+"\n") print "[+]",send_item print read_until(f).strip() print read_until(f).strip() print "----------------" time.sleep(0.1) continue s.send(send_item+"\n") print "[+]",send_item print read_until(f).strip() print "----------------" time.sleep(0.1) s.close() f.close() if __name__ == "__main__": main()
The flag is "flag{ch3ck-exp3rian-dat3-b3for3-us3}"
baby_crypt ( Crypto 350 )
crypto.chal.csaw.io:1578 にnetcatにアクセスする.usernameを入力するとクッキーを発行してくれるというだけのサーバが動いている.
問題文に
The cookie is input + flag AES ECB encrypted with the sha256 of the flag as the key.
とあったみたいなのだが,私は完全に見落としていて入力検証から始めた.(途中で追記されたものと信じたい)
ひたすら入力検証をしていると以下のことが分かった.
- クッキーの長さは入力の長さに依存
- 長さは16文字おきに変化し,その差は32文字
- "a"*16個と,"a"*32個の時のクッキーを比較すると前のブロックに依存していないことが分かる
- 同じ長さの複数の入力を比較したとき,後ろ32文字が同じ
1.から,クッキーは入力を共通鍵暗号などで暗号化されて作られているのではないかということはわかる(自明という説もある).2.から,1ブロック16文字のブロック暗号ではないかと推測できる.3.によりモードはECBであることが分かる.4.により,パディング以外に後ろに何かくっついていることが分かる.
もう少し詳しく説明すると,3.は以下のような検証をした.
Enter your username (no whitespace): aaaaaaaaaaaaaaaa # "a"*16 Your Cookie is: 469ac6eba774ac471777f35c88d9dd6a / f9cc1330ae5830732a18d1a23211ffbce3725519adb9e6f10d658d87c80825ed Enter your username (no whitespace): aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa # "a"*32 Your Cookie is: 469ac6eba774ac471777f35c88d9dd6a / 469ac6eba774ac471777f35c88d9dd6a / f9cc1330ae5830732a18d1a23211ffbce3725519adb9e6f10d658d87c80825ed
もしもCBCモードのようにIVが使われていたり前の暗号化結果が依存するならこのような結果にはならない."a"16個のクッキーの1ブロック目と"a"32個のクッキーの2ブロック目はまず同じにならない(きちんと検証するなら"b"16個+"a"16個などが分かりやすい).
そして,もしもブロック暗号だとすると,基本的にはパディングが施されるので,ブロックごとに分けられた入力の最後はブロック長にパディングされる.しかし,上の結果を見てみると,入力とは関係ない末尾の部分がパディングだけにしては長すぎる.従ってこの問題は,入力の末尾にflagをくっつけた後にパディングをしてAES ECBモードで暗号化してるのではないかという推測をした.
もしそうであれば,flagが"flag{...}"であるとき,以下の二つの入力のクッキーの1ブロック目は同じになるはずである.
- "aaaaaaaaaaaaaaaf" ("a"*15個+"f") -> "aaaaaaaaaaaaaaaf / flag{.....}padpadpad...."
- "aaaaaaaaaaaaaaa" ("a"*15個) -> "aaaaaaaaaaaaaaaf / lag{.....}padpad...."
よって,仮に上のfの部分が未知でも,アルファベットを総当たりすることで1文字特定可能である.あとは以下のようにずらしていけば1文字ずつ特定することが可能である.
- "aaaaaaaaaaaaaaf?" ("a"*14個+"f"+"?") -> "aaaaaaaaaaaaaaf? / flag{......}padpad..."
- "aaaaaaaaaaaaaa" ("a"*14個) -> "aaaaaaaaaaaaaafl / ag{......}padpad..."
?の部分を総当たりすればlで当たるはずである.
実際に推測できる"flag{"の部分を試すと同じになるので,この方針でスクリプトを書いた.なお,フラグが1ブロック長より長い可能性があるのでスクリプトでは"a"*32から始めた.
# coding:utf-8 from m1z0r3.crypro import * import time remotehost = "crypto.chal.csaw.io" remoteport = 1578 s,f = sock(remotehost, remoteport) def get_cookie(username): read_until(f, "whitespace):") s.send(username+"\n") read_until(f, "is: ") return read_until(f).strip() def main(): print 'get_cookie("a"*31+"f")[:64]:' print "",get_cookie("a"*31+"f")[:64] print 'get_cookie("a"*31)[:64]:' print "",get_cookie("a"*31)[:64] print "==== Start ====" ans = "" for i in xrange(1,33): check = get_cookie("a"*(32-i)) for c in readable: if check[:64] == get_cookie("a"*(32-i)+ans+c)[:64]: print "%s文字目は %s"%(i,c) ans+=c break #time.sleep(0.1) if c == "}": break print ans print "congrats!!" print ans if __name__ == "__main__": main()
The flag is "flag{Crypt0_is_s0_h@rd_t0_d0...}"
まとめ
時間中に解いた二つの問題(CVV, baby_crypt)のWrite-upでした.Almost Xorが解けなかったので精進が必要です.
hashcatをCPU OnlyのUbuntu16.06環境にインストール
オープンソースの高速パスワードリカバリーツールであるhashcatをCPU OnlyのUbuntu16.04環境にインストールする手順になります.
環境
hashcatはGPUを利用することでより高速に処理が可能ですが,私のサーバにはCPUしか積んでいないのでCPU環境で使えるようにしました.CPU(やIntel GPU)でhashcatを使う場合には,OpenCLという並列コンピューティングのためのクロスプラットフォームをインストールする必要もあります.下記のインストール手順で順に説明します。
インストール手順
- hashcatのインストール (バイナリ or ビルド)
- OpenCLのインストール
1. hashcatのインストール(バイナリ or ビルド)
hashcatのインストール方法は2パターンあります.すでにコンパイル済みのバイナリファイルをインストールするか,ソースからビルドするかの2択です.せっかくですのでどちらの方法についても記載します.
方法1: バイナリファイルをダウンロードする
Ubuntuで扱う場合はこれが一番簡単だと思います.こちらのサイトの上部にある最新版のバイナリをインストールします.(古いバージョンは最下部にあります)
ファイルは7zで圧縮されています.7zコマンドがあれば下記のようにして解凍できます.7zコマンドが使えない場合はお手数ですが7zのインストール方法を調べて入れてください.
$ wget https://hashcat.net/files/hashcat-3.6.0.7z $ 7z x hashcat-3.6.0.7z $ file hashcat-3.5.0/hashcat64.bin hashcat-3.5.0/hashcat64.bin: ELF 64-bit LSB executable, ...省略...
解凍したフォルダ内のhashcat64.binを使うことができます.
方法2: ソースからビルドする
ソースからビルドする場合は,こちらのGithubのBuild.mdを参考にしました.以下のようにすればインストールできます.
$ git clone https://github.com/hashcat/hashcat.git $ cd hashcat $ git submodule update --init $ make $ sudo make install $ hashcat --version
最後のコマンドでhashcatのバージョンが表示されていれば成功です.
さて,hashcatをインストールできたところで早速ベンチマークを試してみたいところですが,このままでは実行できません.OpenCLをインストールしていないためです.試しに以下のコマンドでOpenCL infoを表示してみると,そもそも以下のようなメッセージが表示され,環境ができていないことが確認できます.
$ hashcat -I ... ATTENTION! Can't find OpenCL ICD loader library ...
細かい出力は忘れてしまいましたが,こんな感じのメッセージが表示されます.(ベンチマークを実行するオプションであるhashcat -bなどでも同様のメッセージが表示され,失敗に終わると思います)
2. OpenCLのインストール
こちらのサイトのOpenCL™ Runtime for Intel® Core™ and Intel® Xeon® ProcessorsにあるOpenCL™ Runtime 16.1.1 for Intel® Core™ and Intel® Xeon® Processors for Ubuntu* (64-bit)をダウンロードします.
こちらはtgz圧縮してるので,以下のように解凍します.
$ wget http://registrationcenter-download.intel.com/akdlm/irc_nas/9019/opencl_runtime_16.1.1_x64_ubuntu_6.4.0.25.tgz $ tar zxvf opencl_runtime_16.1.1_x64_ubuntu_6.4.0.25.tgz $ cd opencl_runtime_16.1.1_x64_ubuntu_6.4.0.25 $ sudo ./install.sh
解凍したフォルダ内にあるinstall.shを実行します.実行後は対話的にインストールを進めていきます.基本的にはdefaultやrecommendを選択していけば良いです.
これでOpenCLのインストールが完了し,hashcatが使えるようになったはずです.以下のコマンドを叩いてみます.
$ hashcat -I hashcat (v3.6.0-117-g99f58f9) starting... OpenCL Info: Platform ID #1 Vendor : Intel(R) Corporation Name : Intel(R) OpenCL Version : OpenCL 1.2 LINUX Device ID #1 Type : CPU Vendor ID : 8 Vendor : Intel(R) Corporation Name : Intel(R) Xeon(R) CPU E5520 @ 2.27GHz Version : OpenCL 1.2 (Build 25) Processor(s) : 1 Clock : 2270 Memory : 1491/5967 MB allocatable OpenCL Version : OpenCL C 1.2 Driver Version : 1.2.0.25
このような出力になっていればインストール成功です.
参考
- hashcat - advanced password recovery
- hashcatの概要やオプション等
- How To Use hashcat On CPU Only
- OpenCL - Wikipedia -
- CentOS に Intel OpenCL をインストールする
本件には関係ないですが,NVIDIA GPU環境でインストール可能なバージョン以外のNVIDIAドライバを入れてしまいUbuntuにログインできなくなった時の対処は以下
OCRツール「Tesseract OCR」をインストールしてPythonで使う
個人的な創作物の中で,「画面のスクリーンショットを取ってその中の文字をOCRで読み取る」ということをしたかったので調べたところ,Tesseract OCRというOCRツールがあることを知りました.しかもPythonライブラリであるpyocrを使うことでPythonからも扱うことができるということで早速使ってみました.
そのインストール手順のメモになります.
OCRとは
OCR(Optical Character Recognition/Reader、オーシーアール、光学的文字認識)とは、手書きや印刷された文字を、イメージスキャナやデジタルカメラによって読みとり、コンピュータが利用できるデジタルの文字コードに変換する技術です。
私の用途的に説明すると,画像データ中の文字をテキストに起こしてくれる技術ということです.
Tesseract OCRとは
OCRツールの一種で,以下の特徴があります.
おそらくPythonに限らずにTesseract OCR(以下,Tesseract)を使えるようなライブラリはあると思います.
Tesseract + PythonでOCRを行う
以下の順で説明していきます.
- 環境
- Tesseractのインストール
- Tesseractを使ってみる
- pyocrのインストールしてPythonで使う
環境
- xUbuntu 16.04
- Python2.7
Tesseractのインストール
今回は確実に最新版をインストールするために,ソースからビルドしてみます.と言っても,Githubに公開されている手順通りにやっていくだけです.また,Githubの手順では自身でトレーニングを行うためのトレーニングツールが必要な人向けの手順も書いてありますが,私は取り急ぎOCRが使えれば良かったため,本記事では飛ばしたいと思います.
まずは依存関係をインストールします.
$ sudo apt-get install g++ # or clang++ (presumably) $ sudo apt-get install autoconf automake libtool $ sudo apt-get install autoconf-archive $ sudo apt-get install pkg-config $ sudo apt-get install libpng12-dev $ sudo apt-get install libjpeg8-dev $ sudo apt-get install libtiff5-dev $ sudo apt-get install zlib1g-dev
次にLeptonicaという画像ライブラリをインストールします.apt-getでも入れられるのですが,Tesseractの最新版では1.74.0が必要になりますので,Leptonicaも最新版をソースからビルドします.ソースはこちらから最新版を得られます.
$ wget http://www.leptonica.com/source/leptonica-1.74.1.tar.gz $ tar xvzf leptonica-1.74.1.tar.gz $ cd leptonica-1.74.1 $ ./configure $ make $ sudo make install
さて,ここまででTesseractをビルドする準備ができました.以下のようにしてビルドします.
$ git clone https://github.com/tesseract-ocr/tesseract.git $ cd tesseract $ ./autogen.sh $ ./configure $ make $ sudo make install
これでTesseractが入りました.
Tesseractは/usr/local/share/配下の訓練データを参照してOCRを行います.Tesseractインストール直後は訓練データがありませんので,こちらから興味のある言語の訓練データをダウンロードしましょう.私は英語と日本語が使いたいので,eng.traineddataとjpn.traineddataをダウンロードし,/usr/local/share/配下に置きました.
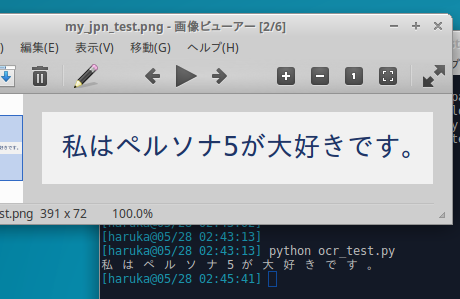
ここまで行うと,コマンドラインからTesseractを使用できるようになります.適当なデータで試してみましょう.私はこのようなデータを使いました.

コマンドは以下です.
$ tesseract my_test.png result
my_test.pngが上の画像ファイル,resultは出力ファイル名です.自動的にresult.txtとなります.結果は以下です.

テスト用の画像作るときも結果を参照する時も同じエディタを使っていてわかりにくいかもですが,ちゃんと読み取れています.
同様に日本語でもやってみます.

コマンドは以下です.
$ tesseract my_jpn_test.png jpn_result.png -l jpn
-l オプションで言語を指定します.結果は以下です.

思ったよりきちんと読み取れています.
(参考にした記事では,複雑な文章等を扱うとはちゃめちゃな結果になるとありました.そのような場合は自分で訓練データを作ると良いそうです.公開されている訓練データも改善されているのかもしれませんね.)
追記)
いくつかの日本語の文章を試してみましたが,やはり英語に比べると精度が低いようです.しかし画像を拡大したりするだけで精度が変わるので,画像中の文字が細かい場合や画像自体が小さい場合は画像を加工すればだいぶ読みやすくなります.
pyocrをインストールしてPythonで使う
では,TesseractをPythonから使ってみます.まずはpyocrをインストール.
$ sudo pip install pyocr
これでPythonでTesseractを扱えます.
(参考にした記事ではTesseractをソースからビルドした場合,とあるひと手間必要とのことでしたが,現在は修正されてひと手間がいらないみたいです.)
では,簡単なテストコードを書いてみます.先ほどの日本語のデータでテストしてみます.
import pyocr
import pyocr.builders
from PIL import Image
tools = pyocr.get_available_tools()
tool = tools[0]
res = tool.image_to_string(Image.open("./my_jpn_test.png"), lang="jpn", builder=pyocr.builders.TextBuilder(tesseract_leyout=6))
print res
$ python ocr_test.py 私 は ペ ル ソ ナ 5 が 大 好 き で す 。
このように,コマンドラインから実行した時と同様の結果なります.
ソースコード中のimage_to_stringというメソッドの引数にbuilderというものがあります.さらに中を見ると,pyocrのTextBuilderの中でterreract_layoutというパラメータに6を指定しています.これはTerreractコマンドの-psmオプションにあたるもので,-psm 6 と同義になります.このオプションはpage seg modeの略で,画像をどのように(どんな画像だと思って)読み取るかというものです.以下が各値の対応です(参考).
pagesegmode values are: 0 = Orientation and script detection (OSD) only. 1 = Automatic page segmentation with OSD. 2 = Automatic page segmentation, but no OSD, or OCR 3 = Fully automatic page segmentation, but no OSD. (Default) 4 = Assume a single column of text of variable sizes. 5 = Assume a single uniform block of vertically aligned text. 6 = Assume a single uniform block of text. 7 = Treat the image as a single text line. 8 = Treat the image as a single word. 9 = Treat the image as a single word in a circle. 10 = Treat the image as a single character.
例えば,縦書きのテキストの画像を読み取る場合,virtically aligned textなので5を指定します.精度良く読み取るためには,このようなオプションの値もしっかり設定する必要があるでしょう.
まとめ
Tesseract OCRをxUbuntuにインストールしてコマンドラインで簡単なOCRを行いました.今回はソースからビルドする方法を紹介しました.
また,pyocrをインストールしてPythonからTesseract OCRを使用しました.